- Classification (Class probability estimation)
- Regression (Numerical value estimation)
- Similarity Matching (Recommendation systems)
- Clustering
- Co-occurrence grouping (Market basket analysis or associative rule mining)
- Profiling
- Link Prediction (Graphs or networks)
- Data Reduction (Dimensionality Reduction : PCA, SVD, Factor Analysis)
- Casual Modeling (Cause and effect pairs or groups)
Thursday, September 19, 2013
9 Major Tasks in Data Science
Most problems in Data Science can be grouped under these 9 broad tasks. Of course some problems can also be classified under one or more of these tasks.
Monday, August 26, 2013
Machine Learning as a Service
There are a couple of start-ups working on delivering machine learning as a service. Some of these solutions provide a turn-key data science environment : some data prep, munging, models, predictions and visualizations
Prediction.io - this is an open source machine learning server. It looks like they focus mainly on recommendations and you can build and fine tune your own models
Yhat - build and deploy models with R and Python
BigML - this has a user friendly interface and great visualizations for non-techies. You also have the choice to modify and fine tune your models and can solve both classification and regression problems here
wise.io - they seem to have a wider variety of problems they can tackle. They also have their own optimized Random Forest implementation that showed some impressive stats when benchmarked against R, Weka and Scikit-Learn
Precog - another strong contender in the space. They have a wider variety of type of input data - logs. JSON, NoSQL, etc. They were recently acquired, so their service may be shut down.
Ersatz - their service uses deep neural networks (black box). Looks like they're still in private beta
Prediction.io - this is an open source machine learning server. It looks like they focus mainly on recommendations and you can build and fine tune your own models
Yhat - build and deploy models with R and Python
BigML - this has a user friendly interface and great visualizations for non-techies. You also have the choice to modify and fine tune your models and can solve both classification and regression problems here
wise.io - they seem to have a wider variety of problems they can tackle. They also have their own optimized Random Forest implementation that showed some impressive stats when benchmarked against R, Weka and Scikit-Learn
Precog - another strong contender in the space. They have a wider variety of type of input data - logs. JSON, NoSQL, etc. They were recently acquired, so their service may be shut down.
Ersatz - their service uses deep neural networks (black box). Looks like they're still in private beta
Tuesday, August 13, 2013
Some Interesting links. Hyperloop, Google n-grams, PredPol
Finally, Elon Musk unveiled some details about the Hyperloop transport system. It would be quite interesting if this makes it out of conception and actually gets built. Right now, California is on the verge of spending more than 10x of what it would cost to build the Hyperloop system, to build one of the slowest high-speed rail systems in the world. A nice infograph of the Hyperloop Transport System
A very detailed Data Mining Map
An interesting visual mashup showing the Start-up Universe This mashup shows everything you'd want to know including company details, funding, VC's, rounds, etc. The data for this mashup is from the CrunchBase API
I recently came across Google's N-gram viewer.It graphs yearly counts of n-grams over the past 200 years. You could literally see when people started using "Donut" over "Doughnuts" link The rise of "Donut" starts at around the same time breakfast chains like Dunkin' Donuts were founded
The Atlas learning environment from O'Reilly. You could read a bunch of tech books both in early release and published.
Predpol, a system that helps predict crime in real time. They claim to place police officers at the right time and place, giving them the best chance to prevent crimes. The systems analyses historical crime data and assigns probabilities of future events / crimes to regions of space and time. This is probably sounding like Tom Cruises' sci-fi thriller, The Minority Report, but without psychics and bathtubs. The system predicts the 'when' and the 'where' of a crime but not the whom. I would not be surprised if the 'whom' can be predicted in the near future. PredPol was designed by scientists at UCLA, Santa Clara, UCI
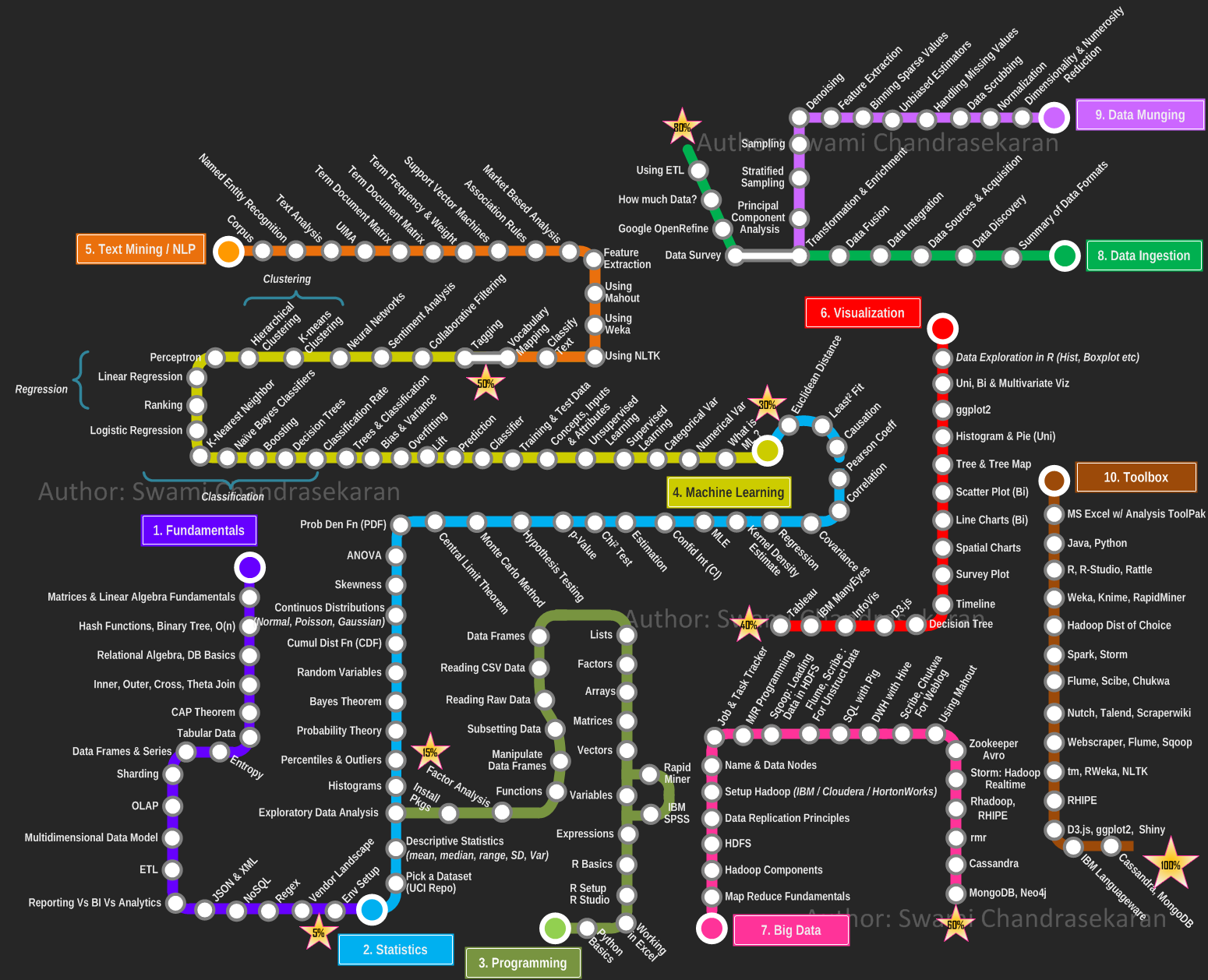
And finally, the road to becoming a Data Scientist can be a long and winding one, Swami Chandrasekaran's take on the Data Science Curriculum

A very detailed Data Mining Map
An interesting visual mashup showing the Start-up Universe This mashup shows everything you'd want to know including company details, funding, VC's, rounds, etc. The data for this mashup is from the CrunchBase API
I recently came across Google's N-gram viewer.It graphs yearly counts of n-grams over the past 200 years. You could literally see when people started using "Donut" over "Doughnuts" link The rise of "Donut" starts at around the same time breakfast chains like Dunkin' Donuts were founded
The Atlas learning environment from O'Reilly. You could read a bunch of tech books both in early release and published.
Predpol, a system that helps predict crime in real time. They claim to place police officers at the right time and place, giving them the best chance to prevent crimes. The systems analyses historical crime data and assigns probabilities of future events / crimes to regions of space and time. This is probably sounding like Tom Cruises' sci-fi thriller, The Minority Report, but without psychics and bathtubs. The system predicts the 'when' and the 'where' of a crime but not the whom. I would not be surprised if the 'whom' can be predicted in the near future. PredPol was designed by scientists at UCLA, Santa Clara, UCI
And finally, the road to becoming a Data Scientist can be a long and winding one, Swami Chandrasekaran's take on the Data Science Curriculum
Monday, February 11, 2013
Wednesday, February 6, 2013
Installing JAGS and rjags on Ubuntu 12.04
I ran into a few issues earlier trying to install JAGS/rjags on Ubuntu. This set of instructions assumes you already have R installed on your system
- Download and Install R (32/64) -bit
- Download the Bayesian Sampling Program JAGS from here : Extract the contents of the tar file and install the JAGS program by running the following commands from the JAGS root folder.
- Download and install the rjags package : I tried install.packages('rjags') in R, which failed initially on my system (Ubuntu). Now, this may work if you're on a Mac or Windows. If you experience the same problems, you need to download the appropriate rjags tar file and and then install it manually. The second line configures rjags for (32/64) bit R. If you are running 32-bit R be sure to replace \lib{64} with \lib and for 64-bit R replace \lib{64} with \lib64. This is very important as you could lose a few nights of sleep here trying to figure out why you can't link the rjags library with the JAGS program. This comes courtesy of Rrasch.
- JAGS is a program that is used for the analysis of Bayesian Hierarchical Models using MCMC (Markov Chain Monte Carlo) Simulations. I used JAGS over BUGS(WinBUGS/OpenBUGS) because it is cross platform, runs on Linux and it appears to be more robust among other reasons.
Thursday, January 10, 2013
CES 2013
While it would be really fun to follow the technology pilgrimage to Las Vegas every January, that's not always possible. Instead, I'll highlight a few of the ideas and gadgets from CES that I have found interesting.
Nest The smart thermostat. They've been around for a while. This thermostat helps you save on energy by learning your usage patterns and it looks really cool.
Aeros. They let you watch live TV over the internet for $8/month or $80/year. Finally a cord cutting alternative that doesn't break the bank. They capture over the air signals and give you access to about 30 channels. Currently only available in the New York area, but are expanding across the country

Liquipel Everyone probably know someone who's lost a phone to water. Liquipel applies a nano coat to your phone or tablet to protect them from liquid spills
Lockitron Keyless entry powered by your phone. You could literally open your apartment door from any where in the world
Nest The smart thermostat. They've been around for a while. This thermostat helps you save on energy by learning your usage patterns and it looks really cool.
Aeros. They let you watch live TV over the internet for $8/month or $80/year. Finally a cord cutting alternative that doesn't break the bank. They capture over the air signals and give you access to about 30 channels. Currently only available in the New York area, but are expanding across the country

Liquipel Everyone probably know someone who's lost a phone to water. Liquipel applies a nano coat to your phone or tablet to protect them from liquid spills
Lockitron Keyless entry powered by your phone. You could literally open your apartment door from any where in the world
Tuesday, December 18, 2012
Some Interesting Videos / Talks
Interesting talk by Jeff Hammerbacher on some of the things he's doing with Data Science in Healthcare / Genomics
I have recently become a huge fan of Nate Silver and Statistical Bayesian Inference. He recently gave a talk at Google
I have recently become a huge fan of Nate Silver and Statistical Bayesian Inference. He recently gave a talk at Google
Saturday, November 10, 2012
Nate Silver and the new Numerati
By now, we probably all know who Nate Silver is. He correctly forecast the result in 49 out of 50 states and all 35 US Senate Races in the 2008 election cycle and all 50 states in the 2012 election cycle. How did he do this? Bayesian Analysis. Ignore all the political pundits.. Nate simply removed the noise from the true signals.
You can check out his 538 blog at the New York Times for more details.

We have also learned that the Obama campaign engaged in a massive data mining operation with micro - targeting and voter segmentation that many could say helped them win. They hired Data Scientists to build predictive models for everything from potential voter turn out, potential voters, fund raising through email campaigns to finding out which email campaigns raised the most money and why. This was recently featured in Time Magazine. If 2008 was the Facebook election, you could say 2012 was the data election.
Nate recently published a book 'The Signal and the Noise' . It should make for an interesting read.

We have also learned that the Obama campaign engaged in a massive data mining operation with micro - targeting and voter segmentation that many could say helped them win. They hired Data Scientists to build predictive models for everything from potential voter turn out, potential voters, fund raising through email campaigns to finding out which email campaigns raised the most money and why. This was recently featured in Time Magazine. If 2008 was the Facebook election, you could say 2012 was the data election.
Nate recently published a book 'The Signal and the Noise' . It should make for an interesting read.
Wednesday, October 31, 2012
Slides from “Survey of Text Mining / NLP in R” talk #rstats
Here are my slides from Survey of Text Mining / NLP in R talk delivered at the October Meetup of the Austin R User Group
Friday, November 25, 2011
Some great resources on the web covering Machine Learning, Data Mining, R, Python and other topics
These are just a few web resources around Python, R, machine learning, data mining, and some other technical topics I've come across. I will update this list as time permits. In the mean time..enjoy!!
Some Good R videos
A collection of talks given by Hadley Wickham @hadleywickham on R
Stanford OpenClassroom - a bunch of CS classes Stanford. Full Courses Short Videos
List of freely available programming books
KDNuggets - latest KD news
Khan Academy application of machine learning to assess student mastery
CMU Machine Learning course
Quick Python Facts
Invent Your Own Computer Games with Python
Courtesy of @jeremyphoward
Getting in Shape for the sport of Data Science
Courtesy of @hackingdata
UCB Intro to Data Science
A good list of Machine learning, Statistical computing related courses
A great video with Jeff Hammerbacher detailing the future of Big Data
Courtesy of @peteskomoroch
Hidden Videos Courses in Math, Science and Engineering
Updated List of Datasets and Video Lectures
Some Good R videos
A collection of talks given by Hadley Wickham @hadleywickham on R
Stanford OpenClassroom - a bunch of CS classes Stanford. Full Courses Short Videos
List of freely available programming books
KDNuggets - latest KD news
Khan Academy application of machine learning to assess student mastery
CMU Machine Learning course
Quick Python Facts
Invent Your Own Computer Games with Python
Courtesy of @jeremyphoward
Getting in Shape for the sport of Data Science
Courtesy of @hackingdata
UCB Intro to Data Science
A good list of Machine learning, Statistical computing related courses
A great video with Jeff Hammerbacher detailing the future of Big Data
Courtesy of @peteskomoroch
Hidden Videos Courses in Math, Science and Engineering
Updated List of Datasets and Video Lectures
Saturday, September 10, 2011
Project Timbutku is now Texas A&M Data Wranglers !!!
It's official, Project Timbuktu is now Texas A&M Data Wranglers (TADW). TADW is now an officially approved student organization. We are still going through the recognition process and will be wrapping that up in the next week.
It's quite exciting to see we have come this far. I've been talking to a couple of people about TADW and I'm quite encouraged with the feedback I'm getting.
Now the real work begins.. find some industry speakers, sponsors, and funding.
By the way we are on the web, on twitter @txdatawranglers and linkedin
For more information about our student organization see this PDF
It's quite exciting to see we have come this far. I've been talking to a couple of people about TADW and I'm quite encouraged with the feedback I'm getting.
Now the real work begins.. find some industry speakers, sponsors, and funding.
By the way we are on the web, on twitter @txdatawranglers and linkedin
For more information about our student organization see this PDF
Sunday, July 10, 2011
What I'm doing this Summer
The long summer is upon us and I'm taking the much needed break from school. Though I'm still keeping really busy. This is a rundown of some of the things I'll be doing / working on this summer.
- I'm interning at a startup company in the employment science space @rezscore as a Data Scientist Intern, They employ statistical and scientific techniques to grade resumes and match them to job descriptions. The free resume grading service also offers suggestions on how you could make some improvements to your resume. I'm having to implement supervised and unsupervised machine learning and data mining algorithms to classify and score the resumes. It's been a lot of fun. I'm doing most of my work in Python and use R, SQL, Excel and SAS as needed to clean and structure data. (I will blogging at length later about techniques and steps in the data cleaning / structuring process and other tips and trick figured out along the way)
- I will be attending Scipy 2011 in Austin, TX . I'm really looking forward to the conference as this is my first professional Python conference, and this will also give me the chance to reconnect with friends in Austin.
- I an working on creating a student club at A&M from Fall 2011. The objective and vision of the organization will be to bring like-minded students together in a collaborative environment to work on interesting data science / Big Data problems. I'm tagging this, Project Timbuktu for now. Jumping through administrative hoops, finding an advisor and securing funding for the organization will not be an easy task especially in the current climate where departments are slashing budgets and expenses. More on Project Timbuktu later.
- I will also be attending PyTexas 2011. This is actually at the end of the summer / early September in College Station
- I attended a startup lessons / Lean startup conference at Austin Tech Ranch (startup incubator) early in the summer. This was basically a day long telecast conference which featured several startup big hitters. More on this later.
Tuesday, April 12, 2011
Hello World !!
For this post, I would like to introduce myself and thank you for stopping by. I'm Ike and I am currently a graduate student at Texas A&M where I am pursing a masters degree in Industrial and Systems Engineering with a focus on computational sciences and data mining.
The exciting world of data is here to stay and I do believe that data analytics is the next frontier in the information age. This point is underscored with the recent emergence of data analytics in social media, healthcare, IT and business.
It's all about the data, and the organizations that are able to leverage this, will remain the few that will continue to evolve and revolve to stay relevant in the marketplace.
It's all about the data, and the organizations that are able to leverage this, will remain the few that will continue to evolve and revolve to stay relevant in the marketplace.
I will be blogging about my thoughts on collective Intelligence, data wrangling, data mining, predictive modeling, social media, start-ups, analytics and also pen down ideas, things I hope not to forget, projects I'm currently working on and experiences.
I'm really excited about this venture.
I'm really excited about this venture.
Subscribe to:
Posts (Atom)